
1. Generative AI의 비즈니스 적용 현황
GenAI는 지난 2년 간 탐색과 실험의 과정을 거쳐, 구체적인 비즈니스 임팩트 단계로 진입
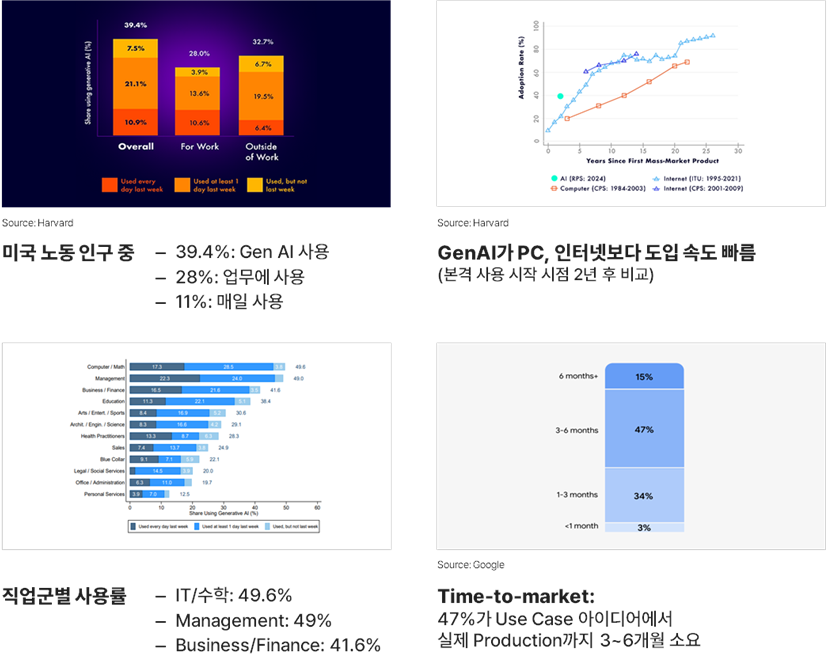
GenAI의 도입은 과거 PC나 인터넷보다 훨씬 빠른 속도로 진행되고 있다. IT나 수학 관련 직업군 뿐 아니라 일반 비즈니스 직군에서도 50%에 가까운 비율이 이미 사용하고 있을 정도다.
많은 글로벌 기업에서도 GenAI를 실제로 업무에 도입했으며, 실질적인 성과로 이어지고 있음을 발표했다. 최근 실적 발표 포럼에서 Meta는 페이스북과 인스타그램에 GenAI 기반 동영상 추천 기능을 추가한 결과로 사용자가 머무르는 시간이 각각 8%, 6% 증가했다고 밝혔다. Google 또한 새로 만드는 프로그램의 ¼ 이상을 GenAI 먼저 만든 후 사람이 검토하는 방식으로 생산하고 있으며 생산성 향상에 큰 도움을 얻고 있다.
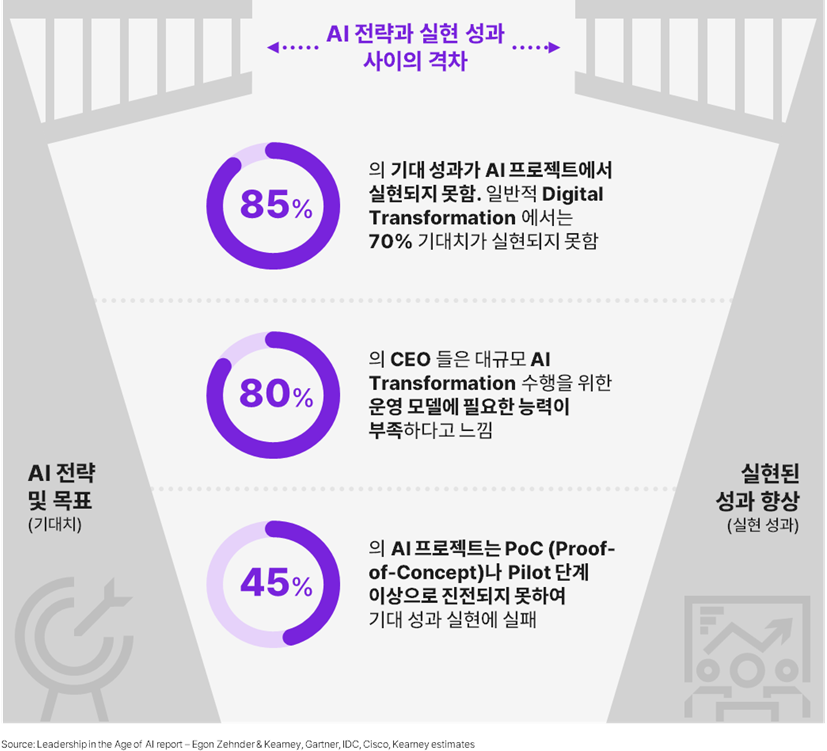
그러나 비효율적 운영 모델이 AI 전략 실행 방해, 성과가 기대치에 못 미치는 결과가 대다수
CEO 대상 설문 결과에 따르면, AI 프로젝트의 85%가 기대 성과만큼 실현되지 못했다는 답변이 나왔다. Digital Transformation 또한 마찬가지의 결과를 보였다. 조직 내부적으로 대규모 AI Transformation을 수행할 운영 모델에 필요한 능력이 부족하다고 답한 응답자가 전체의 80%를 차지했다. 또한 45%의 AI 프로젝트가 PoC나 MVP 단계에서 더 진전되지 못해 비즈니스 성과 실현에 한계를 느낀다는 답변이 있었다. 이 설문 결과를 통해 얻을 수 있는 인사이트를 정리하면, AI 적용 성공의 열쇠는 어떤 기술을 적용하는가(What)가 보다는 어떻게 적용하는가(How)에 좌우한다는 것이다.
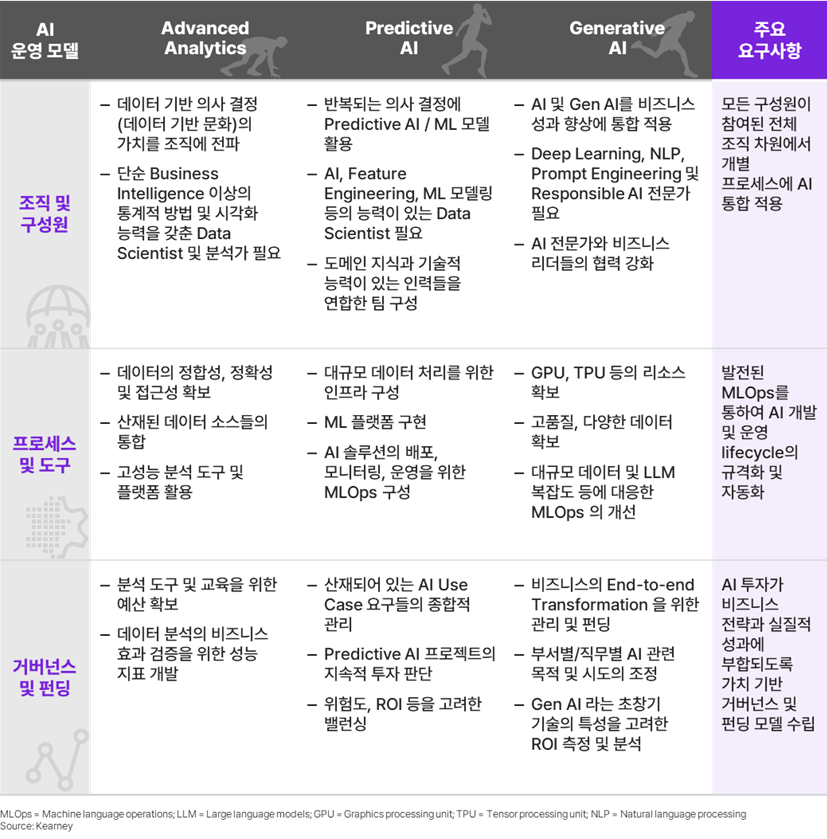
AI, 특히 Gen AI는 무한한 가능성을 지녔지만, 운영 모델의 개선이 요구됨
AI의 Use Case를 선정하고 개발하는 것 이외에, AI를 활용해 전사적으로 비즈니스 성과를 만들 수 있도록 최적화된 운영 모델을 마련하는 것이 필요하다. AI 운영 모델을 최적화하기 위해서는 ‘조직 및 구성원의 능력 개발’, ‘프로세스 및 도구 개편’, ‘기술에 대한 투자와 책임 있는 거버넌스’ 3가지가 병행되어야 한다.
2. AI 운영 모델 개선을 위한 7가지 선택 사항
GenAI 운영 모델을 개선하려면 조직의 AI Journey 전반에 걸쳐 최적의 선택이 필요
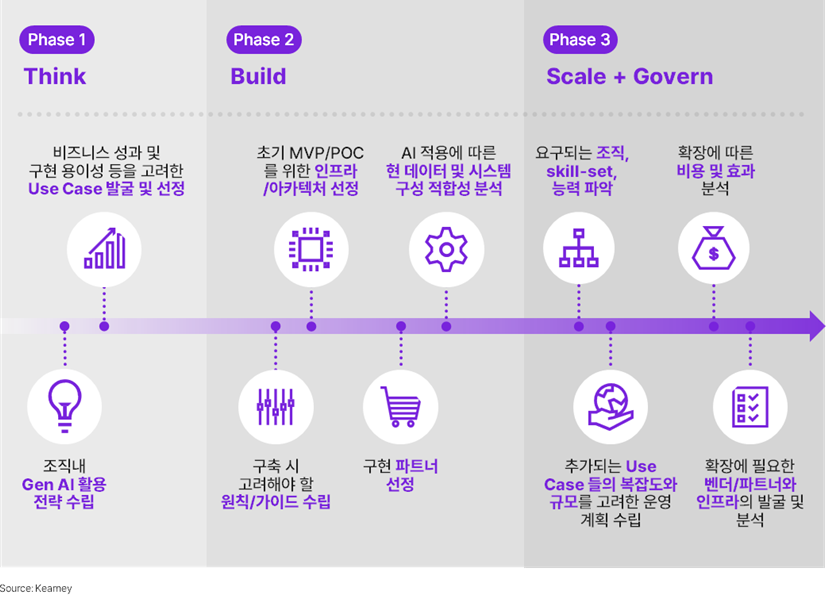
조직의 AI Journey는 전략을 수립하고 Use Case를 발굴하는 ‘Think’ 단계, MVP/PoC를 만들고 시스템에 구현하는 ‘Build’ 단계, 그것을 운영하고 확장하는 ‘Scale+Govern’ 단계로 나눌 수 있다. 각 단계별 선택 사항 중 중요한 7가지를 골라, 사례를 통해 최적의 선택을 분석해보고자 한다.
► 조직의 AI journey
Phase 1 - Think
AI 프로젝트 수행 조직 구성, 중앙화(Centralized) vs. 부서별/직무별 분산화(Distributed)?
AI의 성공은 기술력 뿐 아니라 비즈니스 프로세스 혁신이 병행되어야 하는데, 부서 내부에 한정된 Use Case만 개발해서는 진정한 가치를 실현하기 어렵다. 각 부서별/직무별로 흩어져 있는 개선 사례를 전사적으로 확장해야 한다. 예를 들어, 고객 응대 담당 부서에서 취합한 VOC의 카테고리를 분류해 데이터화 했다면, 해당 부서 뿐 아니라 마케팅, 생산, 디자인, 품질 등 타 부서와 공유되어 함께 활용되어야 그 가치를 높일 수 있다.
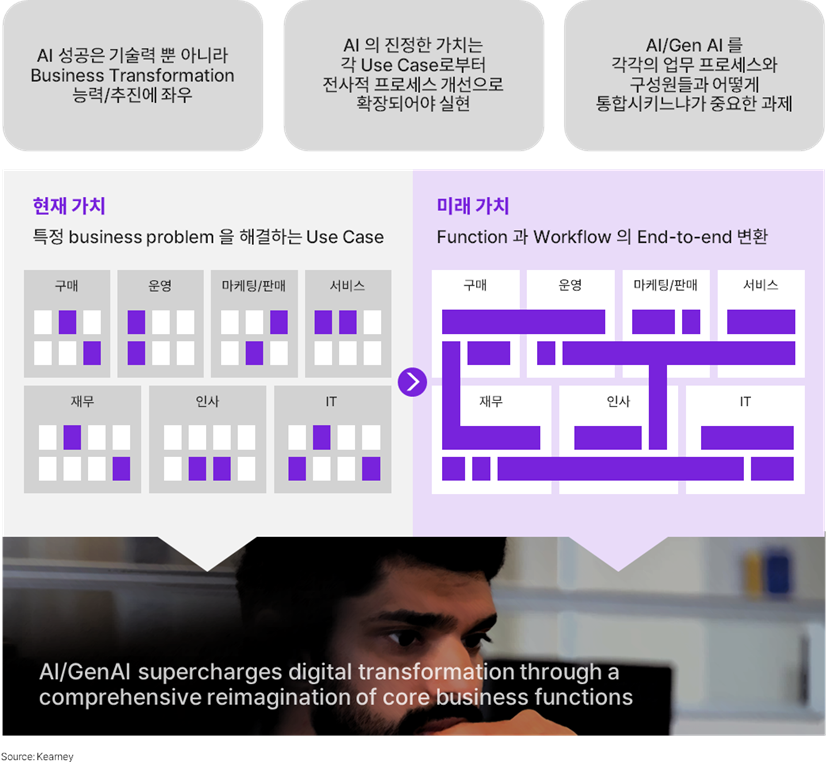
AI 프로젝트 또한 다른 Digital Transformation과 마찬가지로, 기술이 아닌 ‘비즈니스 문제점 혹은 목적’으로부터 출발해야 한다. 따라서 실질적인 성과를 위한 조직 구성의 한 방법으로 기술 인력 및 비즈니스 전문가가 한 팀이 되는 ‘AI Squad’ 방식을 적용할 수 있다.
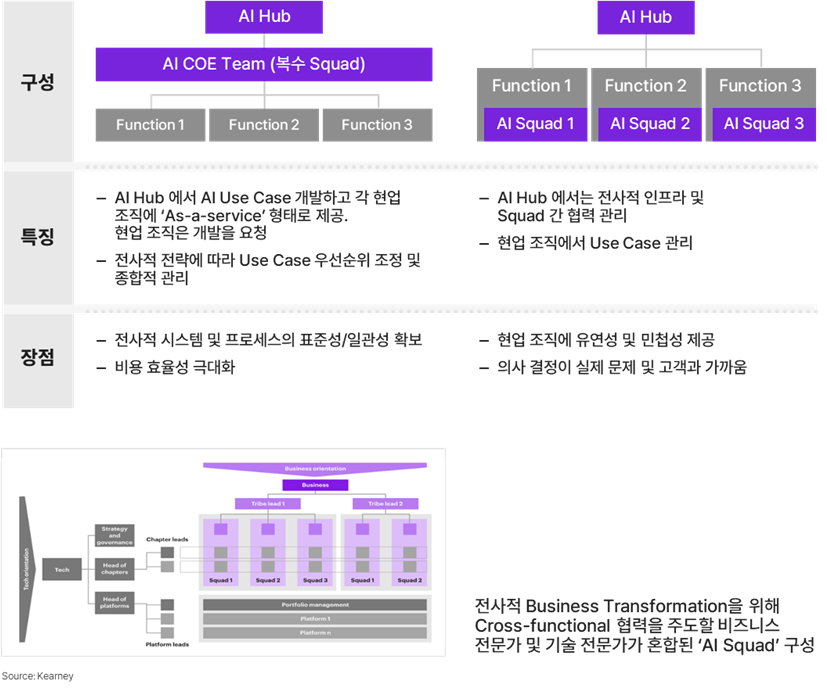
‘Squad’는 세계 최대 스트리밍 업체인 Spotify에서 시작된 조직으로, 애자일과 비슷한 개념이지만 애자일 조직보다 더 작은 조직이다. 기능 조직(부서) 단위보다 더 작게 구성되어, 각 부서의 AI과제를 추진하는 작은 조직을 말한다. 하단 그림과 같이 각 AI Squad에 속한 기술 및 비즈니스 전문가들은 타 Squad와 정보를 공유하며 노하우를 습득하고 능력을 향상시킬 수 있다.
AI 분야는 아직 성장 초기인만큼 아직 전문가가 부족하므로, 각 AI Squad를 아우르는 전사적 AI Hub 그룹이 있으면 더 효율적으로 관리하고 운영할 수 있다. 왼쪽 그림과 같이 Squad가 집중된 형태로 각 기 능부서의 프로젝트가 있을 때 협력하는 방법이 있으며, 오른쪽과 같이 각 Squad가 부서별로 배치되어서 함께 운영하는 방법이 있다. 얼핏 복잡해 보이지만, 핵심은 크로스 펑셔널(cross-functional)이다. 기술 전문가와 비즈니스 전문가가 함께 참여하는 작은 실행 조직을 두고, 그것을 아우르는 허브를 구성하여 전사적으로 Use Case 개발 전파, 운영 효율을 높일 수 있음을 보여준다.
Phase 1 - Think
Use Case 선정 시, 비즈니스 성과 vs. 구현 용이성?
비즈니스 성과와 구현 용이성은 Use Case를 선정할 때 가장 고민해야 할 부분이다. Gen AI의 응용 분야는 아래 표에 정리한 것처럼 각 분야별, 도메인별, 산업군 별로 많은 Use Case가 있다.
► Gen AI 응용 분야

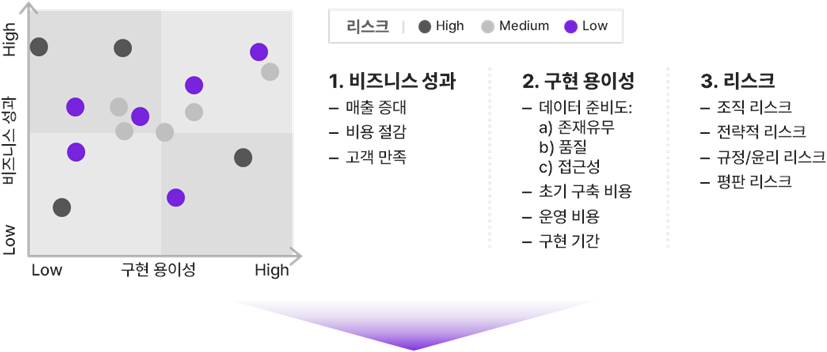
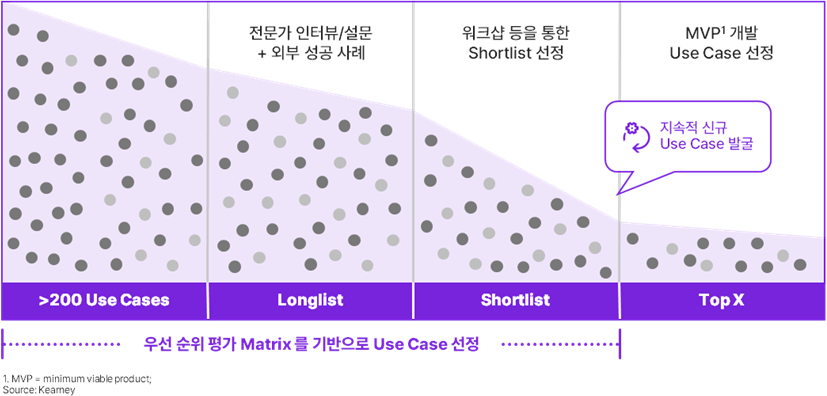
Use Case를 선정 및 평가할 때는 ‘비즈니스 성과’, ‘구현 용이성’, ‘리스크’ 3가지를 기준으로 해야 한다(왼쪽 매트릭스 참고). 모아진 Case들은 분야별 전문가 인터뷰 및 벤치 마킹을 통해 1차 필터링하고, AI 전문가와의 워크샵을 통해 2차 필터링 단계를 거쳐 MVP를 추진할 Case를 선정한다(오른쪽 매트릭스 참고). 이처럼 체계적인 평가를 거친 후 우선순위가 높다고 판단되는 Case에 먼저 투자하는 것이 좋다.
► 우선 순위 평가 Matrix
► 우선 순위 funnel
고객센터의 생산성 향상을 위해 Gen AI를 적용할 Use Case를 결정하려는 경우를 예시로 살펴보면, ‘청구서 관련 문의’가 최상위 우선순위로 평가되어 있다. 구현 용이성은 낮지만, 콜 빈도가 높고 콜당 처리 비용이 비싸기 때문에 먼저 투자하기에 적합하다. ‘단순 계좌 잔고 문의’는 구현하기는 쉽지만, 콜당 처리 비용이 낮기 때문에 ROI 면에서는 가치가 높지 않을 수 있다. 하지만 아직 조직 내 Gen AI 역량이 성숙하지 않은 상태에서 첫 시도라면, ‘단순 계좌 잔고 문의’가 더 좋은 선택일 수 있다.
많은 조직에서 Gen AI 첫 시도를 내부 직원용으로 할지, 대 고객 서비스로 할지 고민한다. 내부 직원용으로 적용하면 더 실수가 있거나 성능이 부족해도 괜찮다는 점에서 리스크는 낮지만 기술적 임팩트도 낮다. 그러므로 조직의 상황과 Use Case의 특성을 분석하여, 리스크와 임팩트 간 균형을 맞추는 지점을 찾는 것이 중요하다. 예를 들어, 미국의 세계 최대 음식 배달업체 Door Dash는 콜센터에 Gen AI를 도입했는데, 일반 고객이 아닌 배달원(Door Dasher) 대상 콜에 우선 적용했다. 그 결과, Peak Demand인 세금 보고 시즌에 상담사가 필요한 콜 수를 크게 줄이는 큰 성과를 냈다. Door Dash는 이 성과를 바탕으로 Gen AI를 대고객용으로 확대하기 위해 준비중이다.
► 예시: 고객 컨택 센터 생산성 향상 Use Case 우선순위

Phase 1 - Think
Use Case에 적용할 기술 선정 시, 전통적 AI(Machine Learning) vs. 생성형 AI(Gen AI)?
Use Case를 선정하고 나면 구현을 위한 기술적 고민이 시작된다. 우선, 선정된 케이스에 전통적 AI와 생성형 AI 중 무엇이 더 적합한지 판단해야 한다. 각각의 특징은 일반적으로 아래와 같이 정리할 수 있다(하단 표 참고).
쉽게 말해, 눈에 보이는 숫자나 데이터가 있지만 의미 파악이나 패턴 발견이 쉽지 않은 문제는 전통적 AI가 적합하다. 반면 글이나 이미지로 표현이 되어 있어 사람이 오랜 시간을 투여하는 경우 처리할 수 있는 문제는 생성형 AI가 더 적합하다.
하지만 조직의 상황에 따라 다르며, 특히 문제를 쪼개어 각 세부 단계별로 전통적 AI와 생성형 AI를 복합적으로 사용하는 경우도 많다. 예를 들어, 해외의 한 통신사의 경우 수많은 네트워크 장비에서 오는 실시간 신호 및 로그를 분석해 네트워크 이상을 감지하는 단계는 전통적 AI로 구현하고, 해당 이상을 해결하기 위해 과거 사례를 검토해 추천 해결방안을 제시하는 단계는 생성형 AI로 구현했다.
► 전통적 AI(Machine Learning) vs. 생성형 AI (Generative AI)

AI에는 머신 러닝(Machine Learning), Neural Networks, Gen AI 등 여러 기술이 있으며, 각 Use Case별로 가장 적합한 것을 선택하는 것이 좋다. 또한 AI가 아닌 다른 data-driven 기술을 융합 적용하는 것도 고려할 수 있다. 예를 들어, AI 등장 이전에 많이 쓰이던 Rule-based 접근, 통계적 접근은 기존 전문가들의 노하우가 충분히 축적되어 있고, 큰 투자 없이도 바로 사용 가능하다는 장점이 있으므로 여전히 활용 가치가 높다. 따라서 AI 영역과 기존의 기술 영역을 융합하여 가장 효율적인 솔루션을 찾는 것이 필요하다.
► 통신사 예시

전통적 AI(ML)와 생성형 AI를 복합 적용한 사례로, 해외 대규모 석유화학 업체의 Case가 있다. 석유화학 공장에서 작업자들이 안전장치를 갖추지 않고 높은 곳에 올라가 추락사를 하는 사고가 발생하여, 이를 방지하기 위한 AI 솔루션을 요청한 사례가 있다. 이 Case에서 첫번째로 고려할 수 있는 선택지는 생성형 AI이다. 아래와 같은 사진을 ChatGPT에 넣은 후, 안전 수칙을 지키고 있는지 여부를 질문하면, 상세한 답변이 도출된다. 이런 결과를 보면 생성형 AI를 도입해 문제를 해결할 수 있을 것처럼 생각하기 쉽지만, 그렇지만은 않다. 24시간 촬영한 모든 데이터를 생성형 AI로 처리하는 것은 큰 비용이 들며, 생성형 AI의 경우 일반적인 ML보다 반응 속도가 느리기 때문에 안전 수칙 알림에 적합하지 않을 수 있기 때문이다.
이에 대한 솔루션으로 기존의 컴퓨터 비전 ML을 적용해 사람의 움직임을 추적하게 하고, 사다리를 올라가는 모습이 보였을 경우 해당 프레임을 생성형 AI로 판단해 안전 수칙 알림을 줄 수 있도록 하는 구성이 가능하다.
► 전통적 AI(Machine Learning) vs. 생성형 AI (Generative AI)

Phase 2 - Build
개발 및 운영 주체와 인프라 선정 시, 내부 리소스 vs. 외부 파트너/솔루션?
Use Case와 기술 파악이 되었으면, 해당 프로젝트에 필요한 인력과 솔루션 인프라를 어떻게 조달할 것인지 결정해야 한다. Gen AI를 위한 Tech Stack에는 아래와 같이 여러 층위가 있다. 하단에는 클라우드 인프라, 클라우드에 데이터를 저장하고 처리하는 데이터 Layer가 있다. 초기에는 기존의 데이터 Layer 위에 Gen AI, 즉 Foundation Layer를 추가하는 것이 비용적, 시간적으로 효율이 높다. 이후로 AI 역량이 성숙함에 따라, 데이터 Layer에 다른 솔루션을 도입하는 것도 고려해 볼 수 있다.
아직 조직 내에 데이터 Layer가 구성되어 있지 않더라도, 크게 걱정할 필요는 없다. Gen AI의 장점 중 하나는 csv 형태(엑셀)의 단순 데이터도 쉽게 처리한다는 점이다. 또한 각 부서에 흩어져 있는 csv를 취합하고 하나의 형식으로 만드는 부분도 AI의 도움을 받을 수 있다. 최근의 LLM은 코딩도 가능하기 때문에 서로 다른 파일을 취합하여 DB화 하는 프로그램도 쉽게 만들 수 있다.
► Gen AI tech stack
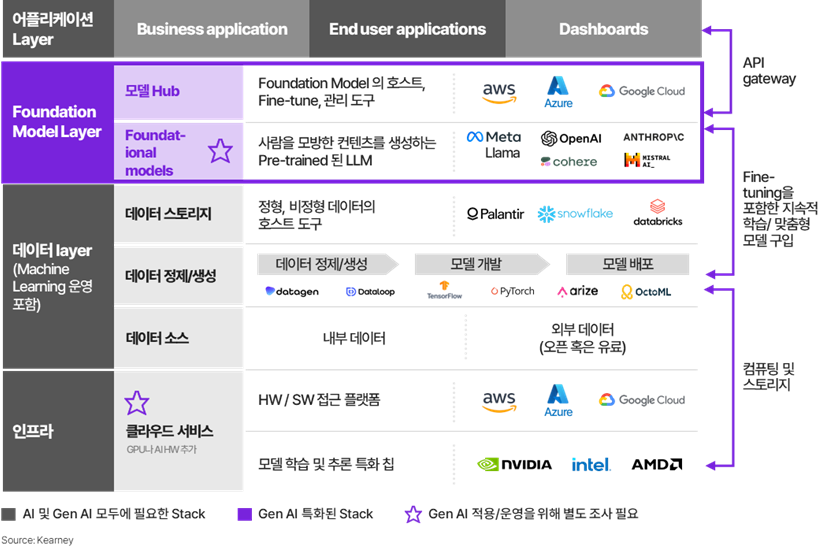
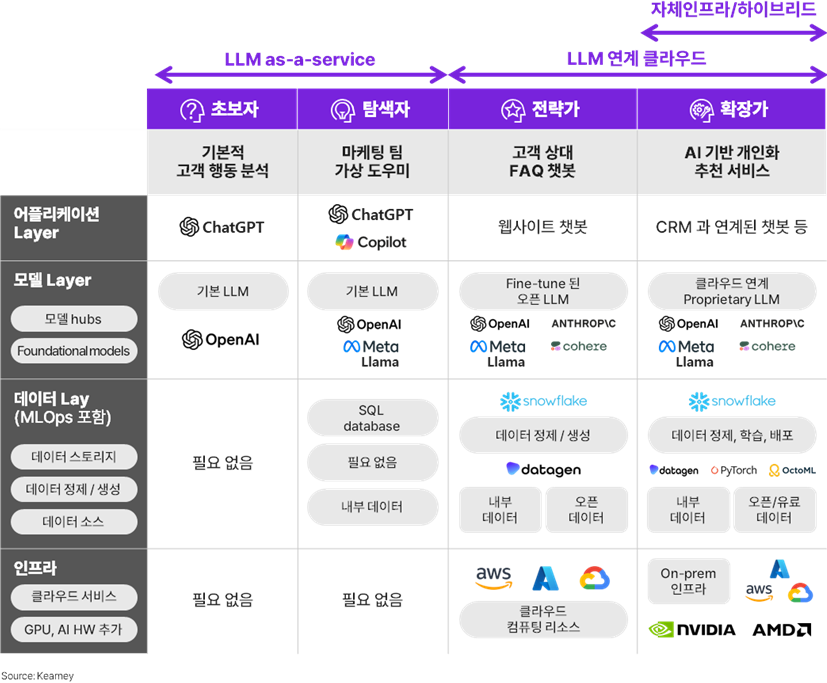
Foundation Layer, 즉 LLM 운영을 위한 인프라 구성에도 여러가지 방식이 있다. 맞춤형 LLM 업체가 제공하는 인프라를 포함한 ‘LLM as a service’는 초기 투자나 별도의 관리가 필요 없지만, 사용하는 API만큼 비용이 나가기 때문에 트래픽이 늘어날수록 부담이 늘어난다. 이런 경우, 자체 인프라를 구축해 LLM 업체의 모델을 직접 운영하는 방식(BYOI)을 선택할 수도 있다. 세 번째로, 현재 우리 모든 시스템이 클라우드에서 돌고 있는 경우, ‘LLM 연계 클라우드’ 구성을 활용할 수 있다. 그런데 다수의 LLM업체는 이미 클라우드 업체와 파트너십으로 엮여 있기도 하다. 예로 OpenAI의 ChatGPT는 MS Azure와 파트너십을 맺고 있으며, Anthropic은 AWS 및 GCP와 파트너 관계이다. 따라서 클라우드에 따라 LLM 선택의 폭에 제한이 있을 수 있다. 마지막은 ‘하이브리드’ 모델로, 평소에는 비용 효율을 위해 ‘As-a-service’ 또는 ‘자체 인프라’ 형태로 운영하다가 피크 시즌에만 클라우드 등 다른 모델을 추가적으로 활용하는 방법이다.
► 맞춤형 LLM 도입/운영 방식

Tech stack 및 기술 조직을 구성할 때, 조직 및 구성원의 AI 능력 및 성숙도를 자체적으로 판단하는 것이 도움이 된다. 성숙도는 아래의 네 단계로 나눌 수 있으며, 어느 단계에 해당하는지에 따라 Tech stack 구현 시 필요한 요소와 고려해야 할 사항이 달라진다.
► 조직 및 구성원의 AI 성숙도

앞에서 본 조직 AI 성숙도에 따라 다양한 인프라와 솔루션을 유연하게 구성할 수 있다. 초기에는 쉽고 효율적인 방법, 오른쪽으로 갈수록 대규모 트래픽이나 점점 더 어려운 Use Case를 활용할 수 있는 인프라이다.
초기에는 Gen AI Tech stack을 갖추었다 하더라도 외부 전문가와의 협업이 적합하다. 예를 들어, 내부 문서 검색용으로 RAG 서비스나 솔루션을 사용하더라도 초기에 틀린 답이 나오면 실망하고 포기하게 된다. RAG 구축은 전반적 평가 지표인 Recall 및 Precision뿐 아니라 Grounding, Correctness, Safety, Relevance 등 단계별 Metric 들이 있으며 각각의 성능을 향상시키기 위한 다양한 고도화 기법이 있다. 전문가와 함께 문제를 하나씩 해결해가며 노하우를 습득하고 조직에 전파하며 조직의 성숙도를 향상시키는 것이 바람직하다.
또한 특정 클라우드와 LLM이 연계된 경우가 많아, 다른 클라우드나 LLM으로 바꾸고 싶을 때 고민이 될 수 있다. 최근에는 클라우드 업체나 LLM업체가 자사 솔루션/서비스 사용 증대를 위해 컨버팅 툴과 솔루션을 지원하기도 한다. 예로, 적용 LLM 을 바꾸고자 할 때, 특정 LLM 에 최적화된 프롬프트를 자동 변환하는 툴을 제공하는 경우도 있다. 따라서 업체를 결정하기 전 이러한 추가 지원도 고려할 필요가 있다.
► 조직의 AI 성숙도 및 니즈 변화에 맞춰 선택적 적용
Phase 2 - Build
Gen AI 모델 선정 시, 상용 LLM(Proprietary LLM) vs. 맞춤형 LLM(Custom LLM)?
인프라 구성과 함께, 어떤 LLM을 사용할 것인지에 대해서도 많은 조직에서 고민하는 부분이다. LLM 선정에는 ChatGPT 와 같은 Proprietary LLM을 사용하거나, 조직의 상황과 도메인에 특화된 Custom LLM을 만드는 등 여러 선택지가 존재한다.
Gen AI 유형은 Input과 Output의 형태에 따라 텍스트에 적합한 LLM 외에도 이미지, 오디오, 비디오에 따라 특화된 모델, 복합 유형 처리가 가능한 Multi Modal 도 많이 나오고 있다. 따라서 Use Case에 맞게 선택할 수 있다.
► 다양한 Gen AI 의 Input / Output 형태 및 Use Case 에 따라 다수의 모델 선택지 (일부 예시)
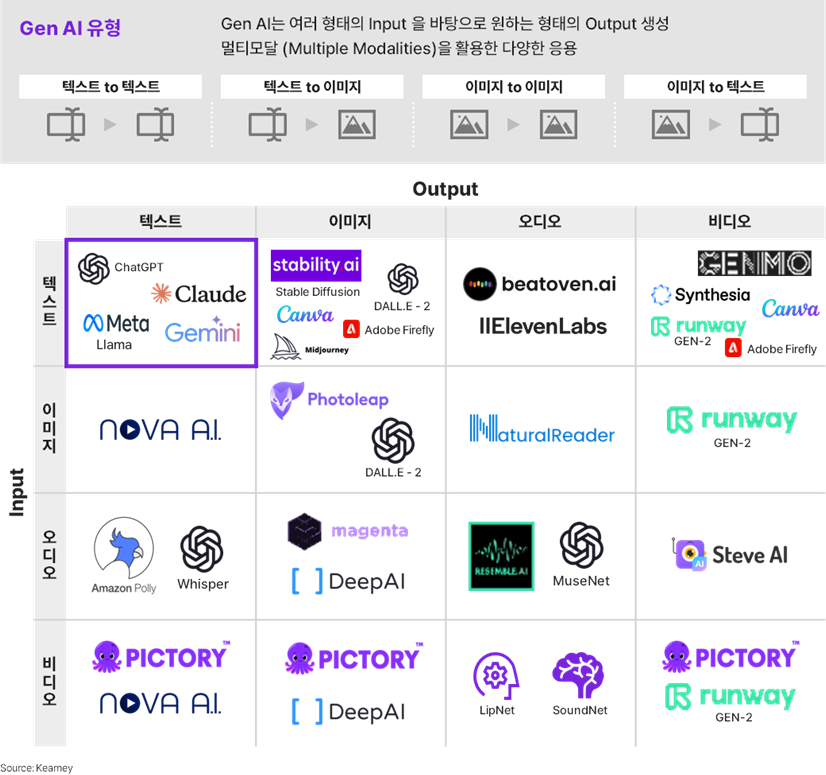
Proprietary LLM 은 바로 사용할 수 있는 범용 모델을 일컫는다. 일반적으로 API를 통해 사용하기 때문에 초기 투자가 적고 빠르게 적용할 수 있지만, 사용량이 증가함에 따라 API 비용도 증가한다.
Custom LLM은 보통 무료 사용을 허용하는 오픈 모델을 파인 튜닝하여 사용하는 것을 말한다. 예를 들어, 싱가폴의 SEA-LION 같은 모델이 있다. 영어권 LLM의 경우, 다양한 동남아시아 언어를 지원하지 않는 제품이 많아 그 부분을 특화하여 파인 튜닝한 모델이다.
► 상용(Proprietary) LLM 과 맞춤형 (Custom) LLM

보통 Proprietary LLM은 프롬프트 엔지니어링을 통해 사용하는 것이 일반적이다. 사람의 소통으로 비유하자면, ‘내일 보고할 재무 보고서를 만들어 와.’라는 명령이 프롬프트이다. 그러나 경험이 없는 신입사원에게 저렇게 지시하면 제대로 된 결과물이 나오기 어려운 것처럼, LLM도 마찬가지다. 따라서 ‘상세 자료와 보고서 양식을 줄 테니 이러이러한 내용을 위주로 정리해 와. 지난 보고서가 있으니 참조하고, 모를 경우 누구에게 물어봐.’와 같이 필요한 데이터를 제공하고, 정확한 명령을 내려야 한다. 이 단계가 바로 프롬프트 엔지니어링이다. 또한, 프롬프트 엔지니어링 단계에서 LLM에게 명확한 Role (‘너는 변호사야’, ‘너는 회계사야.’)을 명시하면 훨씬 더 좋은 결과를 얻을 수 있다.
파인 튜닝(Fine-tuning)이란, 경험이 없는 신입 사원에게 재무 보고서를 만드는 학습을 장기간에 걸쳐서 교육시키는 과정에 빗댈 수 있다. 교육을 시킨 후에 ‘이 자료를 가지고 재무 보고서를 만들어 와.’라고 지시하면 정교한 프롬프트 엔지니어링 없이도 좋은 결과를 얻을 수 있다. 파인 튜닝은 아래와 같이 여러 기술적 기법들이 있으며, 상황에 따라 적합한 기법이 다르다. 한 가지 유의할 점은 파인 튜닝된 LLM은 사용에 효율적이지만, 학습을 시키는 과정에 많은 리소스가 투입되며 무조건 성능이 더 좋아진다는 보장이 없다는 점이다. 파인 튜닝 후 성능을 예측하기 위한 Tip이 있다면, 기존의 데이터들을 프롬프트에 충분하게 넣어 긴 프롬프팅을 적용해 보는 것이다. 적은 프롬프트를 적용했을 때보다 Output이 확실히 좋아진다면, 파인 튜닝이 성공할 확률이 높다.
► Prompt Engineering 과 Fine-tuning

Phase 2 - Build
AI 성능 목표 수치, 88% vs. 99%?
88% vs. 99%란, AI의 목표 성능을 어떤 수치로 잡을 것인지를 말한다. Gen AI 프로젝트를 수행할 때 목표치 성능을 99%로 잡는 경우가 종종 있으나, 그런 경우 프로젝트의 진행이 오히려 어려워질 수 있다. 사람이 직접 처리하거나 기존의 시스템을 이용하는 현재 프로세스 정확도가 88% 정도라면, 목표치를 현재 베이스 라인에만 맞춰도 인건비 절감이나 일처리 속도가 빨라지므로 생산성 향상이 가능하다. 우선은 88%의 목표로 PoC를 진행한 후, 차차 개선해 나가는 방식이 더 효율적이다.
현실적인 목표 설정의 중요성을 보여 주는 예로, 고객 상담센터의 고객 상담용 RAG Gen AI 프로젝트를 수행한 케이스이다. 고객 센터 리드 직원들이 FAQ 질문과 답변 데이터를 작업했으나, 사람이 공부해도 만들어내기 어려운 수준의 답변 데이터를 제시하여, 개발이 어려워진 적이 있다. 따라서 이러한 프로젝트의 경우, 비즈니스 및 기술 전문가들이 초기부터 끝까지 충분한 합의를 거쳐 진행해야 한다. 또한 Evaluation Set과 Framework 역시 중요하다. Evaluation Set에는 실 상황을 잘 반영할 수 있는 분포의 다양성이 반드시 반영되어야 하며, 어렵거나 잘못된 케이스도 포함되어야 한다. 그리고 세팅된 Evaluation Set는 고정된 것이 아니라 중간중간 협의를 거쳐 지속적으로 변화를 반영할 수 있어야 한다.
► AI 프로젝트 수행 Best Practices

Phase 3 - Scale + Govern
안전한 Gen AI를 위한 보호 기능 구축 시, 자동 안전장치(Automated Guardrail)vs. 사람 개입 (Human-in-the-loop)?
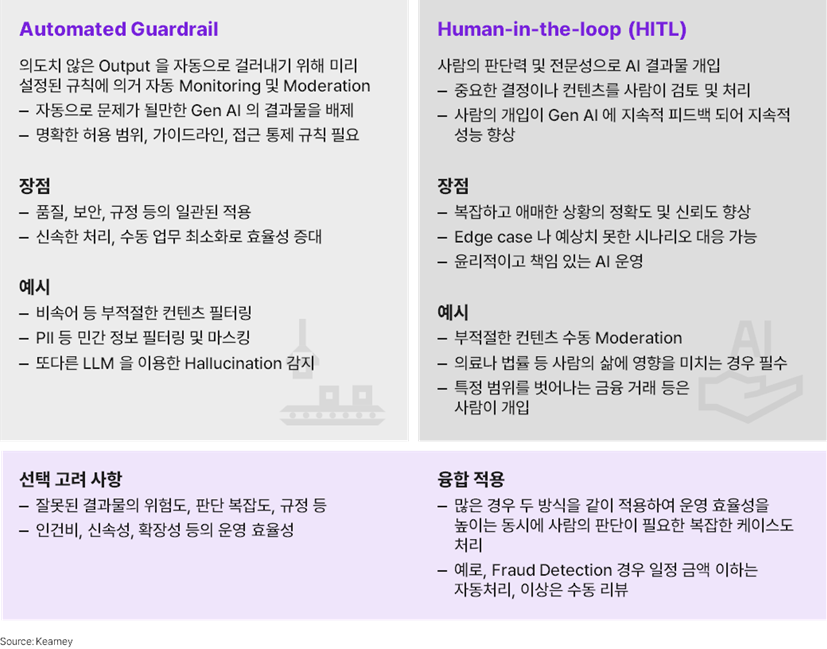
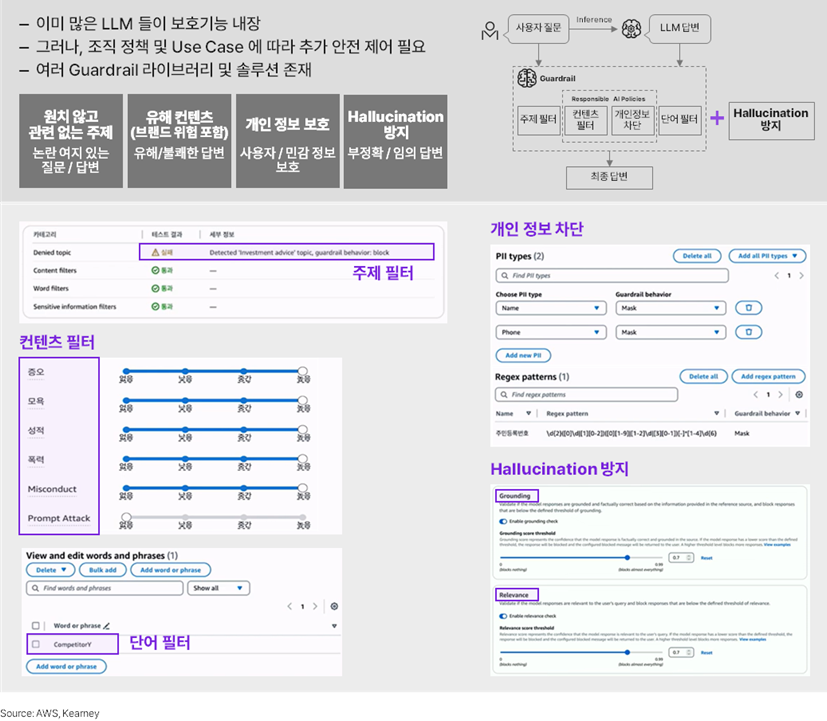
마지막으로, 안정적이고 책임감 있는 AI 거버넌스를 위한 주제이다. 사람도 그렇듯, Gen AI도 완벽하지 않다. 환각 (Hallucination)과 같은 현상이 그 예이다. 따라서 Gen AI를 활용할 때에는 안전 장치, 가드 레일이 반드시 필요하다. 가드 레일을 자동화할 것인지, 혹은 사람이 개입할 것인지도 큰 결정 사항이다.
자동화된 가드 레일은 일관된 품질 보완과 신속한 처리가 가능하며, 인건비도 적게 든다. 반면 사람이 개입하면 상당히 어려운 케이스도 처리할 수 있으며 더 윤리적이고 책임 있는 작업이 가능하지만 효율성은 떨어진다. 따라서 두 선택지를 융합 적용하는 것이 좋다. 즉, 자동 가드 레일을 구축하고, 특정한 기준을 넘는 경우 사람이 개입하는 형태이다. 예를 들어, Fraud Detection을 자동화한 후 일정 금액 이상의 케이스는 사람의 리뷰를 거쳐야만 다음 단계로 넘어가도록 설계하는 것이다.
► Automated Guardrail 과 Human-in-the-loop
많은 LLM에 이미 이러한 안전 장치가 내장되어 있지만, 조직 정책과 Use Case에 맞게 추가적인 구축을 하는 것이 좋다. 대표적으로, 원치 않고 관련 없는 주제에 대한 필터링, 유해 콘텐츠(성적인 표현, 비속어)에 대한 필터링, 개인정보(전화번호, 주민등록번호, 이름, 의료 기록 등) 보호 기능 등이 있다.
아래 사례 이미지에서 보듯이, 원치 않는 주제인 ‘투자 권유’의 내용을 필터링할 수 있으며, ‘증오’, ‘모욕’ 등 특정 주제의 콘텐츠를 개별적으로 필터링할 수도 있으며 각 필터링의 민감도를 설정해 얼마나 엄격하게 제한할 것인지도 설정할 수 있다. 단어는 비속어 뿐 아니라 경쟁사 이름과 같은 단어 수준에서도 필터링 가능하다.
환각(Hallucination) 방지하는 기능은 보통 그라운딩(Grounding)과 렐러번스(Relavance) 를 높이도록 사용된다. 그라운딩이란, 입력된 데이터에 포함된 정보만을 기초하여 답변하도록 하는 것이다. 즉, 매뉴얼이나 문서에 없는 일반적인 정보에 기초한 답변을 하게 되면 환각이 생길 수 있다. 렐러번스는 질문과 관련이 높은 답변을 하도록 하는 것을 말한다. 답을 몰라도 엉뚱한 답을 생성해내서 답변하게 되면 환각이 생기기 때문이다.
► Guardrail 솔루션 (예시)
3. 마무리
단계별 Key Question에 대한 사전 분석/대응이 결과의 차이를 만듦
앞서 정리한 7가지 주제 외에도, Gen AI 적용 스텝별로 아래와 같은 다양한 Key Question이 존재한다. 물론 처음부터 이 모든 질문에 대한 답을 가지고 시작하기는 어렵다. 단, 적용 초기 단계부터 각 단계별 질문에 대해 최대한 고민하고 분석하는 과정을 거쳐 진행하면 Gen AI 적용 성공 확률을 크게 높일 수 있다. 조직의 AI 성숙도가 높지 않은 경우, 외부 전문가의 도움을 받아 함께 시작하는 것도 좋은 방법이 될 것이다.



